Aufgabe 3 - Explorative Analyse und Clustering
In dieser Aufgabe verwenden wir den „wine”-Datensatz. Die Daten sind das Ergebnis einer chemischen Analyse von Weinen, die in derselben Region in Italien von drei verschiedenen Weinbauern angebaut wurden. Es gibt dreizehn verschiedene Messungen für verschiedene Bestandteile, die in den drei Weinsorten vorkommen.
Der wine-Datensatz ist Bestandteil der Bibliothek sklearn.datasets und kann über die Anweisung
wine = load_wine(as_frame=True)geladen werden.
a) Datensatz laden
Section titled “a) Datensatz laden”Importieren Sie alle erforderlichen Bibliotheken und laden Sie den Datensatz.
Von welchem Typen sind wine, wine.data und wine.target?
Lösung:
from sklearn.datasets import load_wine
wine = load_wine(as_frame=True)
print(f"wine: {type(wine)}")print(f"wine.data: {type(wine.data)}")print(f"wine.target: {type(wine.target)}")| Variable | Typ | Beschreibung |
|---|---|---|
wine | Bunch | Sklearn-eigenes Objekt das Datensatz, Labels und Metadaten zusammenfasst |
wine.data | DataFrame | Die Features als Pandas DataFrame (wegen as_frame=True) |
wine.target | Series | Die Zielvariable als Pandas Series (wegen as_frame=True) |
b) Count Plot
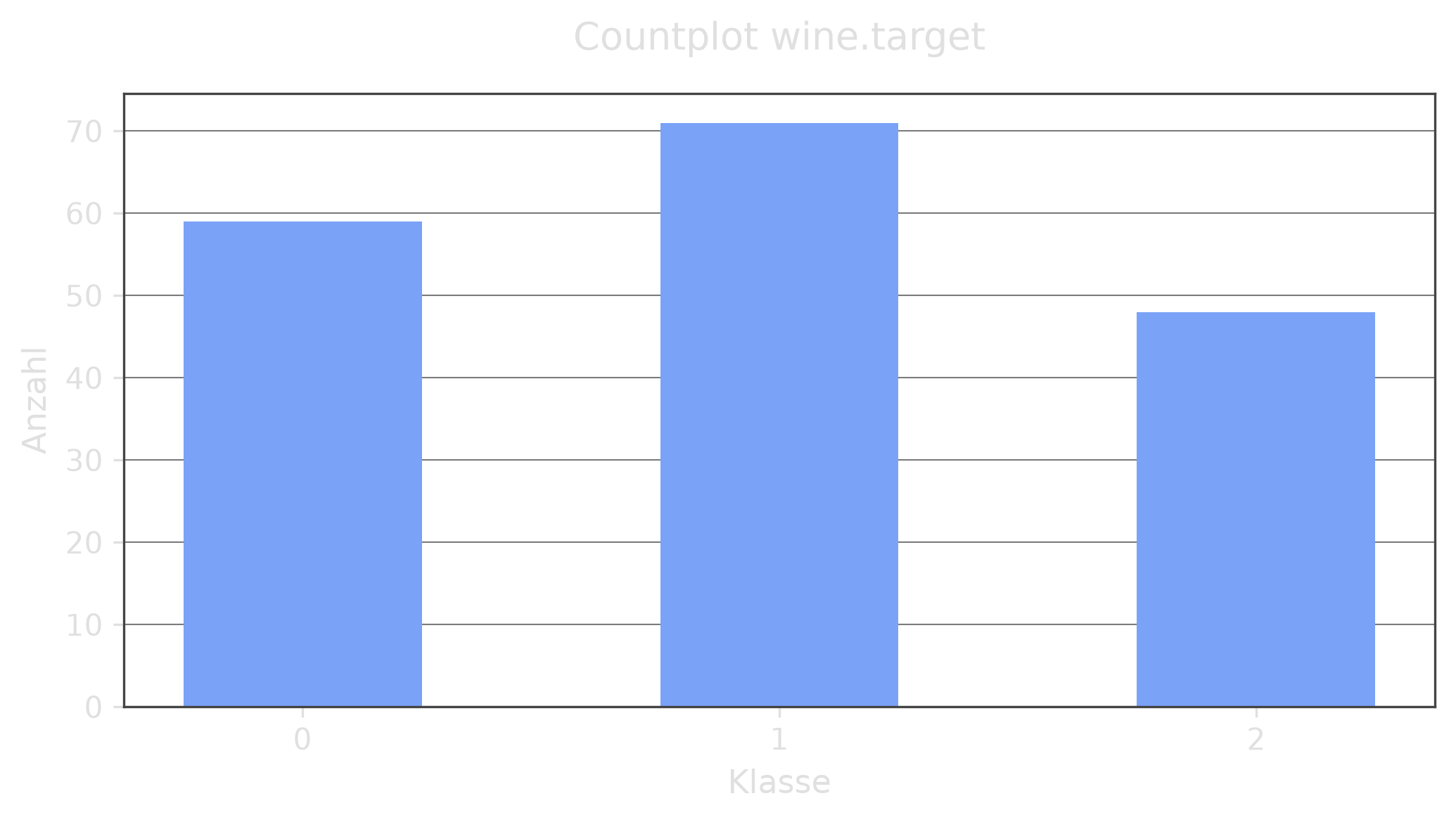
Section titled “b) Count Plot”Erstellen Sie einen Countplot für wine.target.
Lösung:
from sklearn.datasets import load_wineimport matplotlib.pyplot as plt
wine = load_wine(as_frame=True)
# Häufigkeit jeder Klasse zählentarget_counts = wine.target.value_counts().sort_index()
fig, ax = plt.subplots(figsize=(7, 4))ax.bar(target_counts.index.astype(str), target_counts.values)ax.set_xlabel('Klasse')ax.set_ylabel('Anzahl')ax.set_title('Countplot wine.target')plt.tight_layout()plt.show()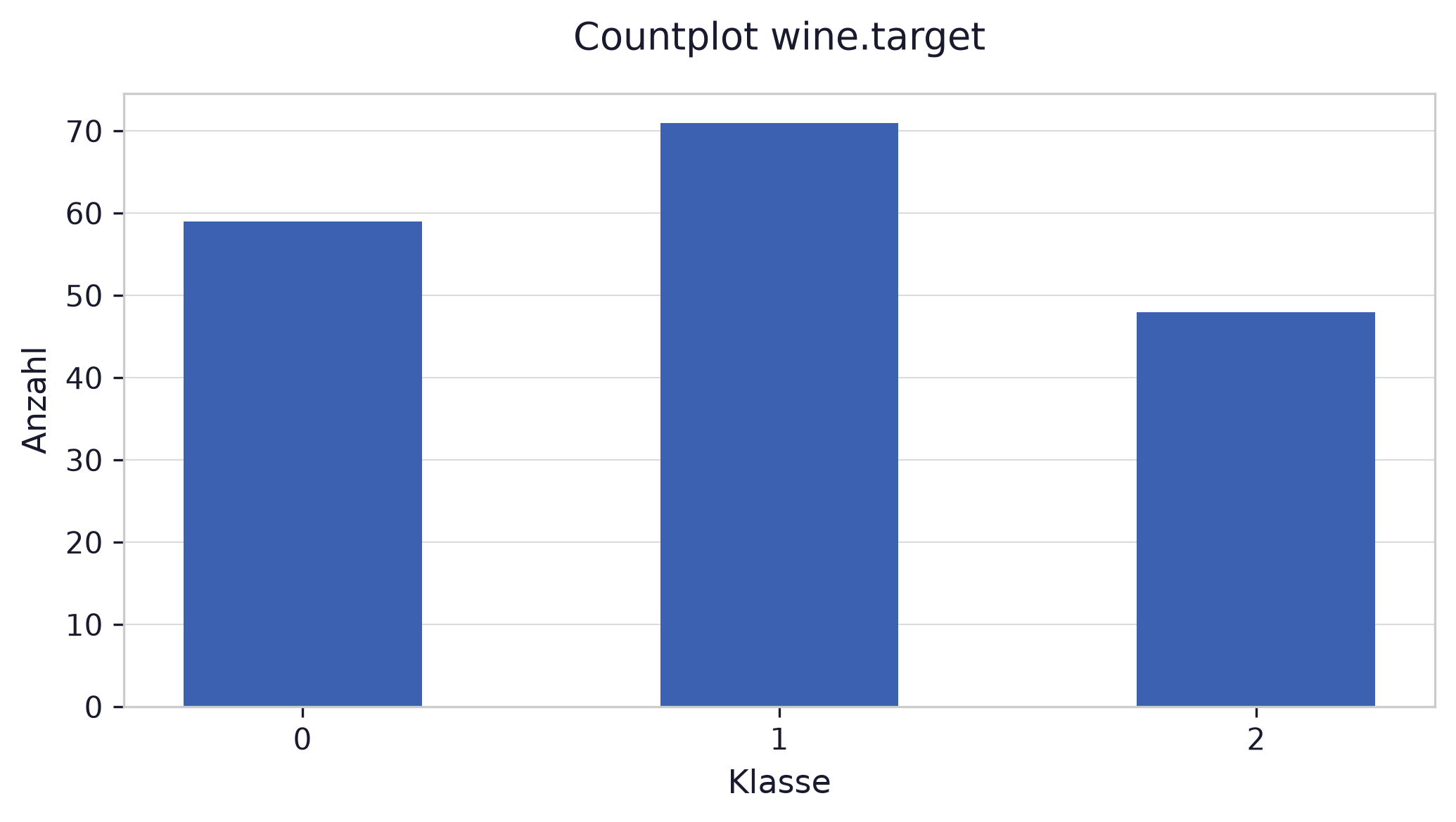
c) Summenstatistik
Section titled “c) Summenstatistik”Erstellen Sie eine Summenstatistik von wine.data. Welche Variable besitzt die größte Standardabweichung?
Lösung:
from sklearn.datasets import load_wine
wine = load_wine(as_frame=True)
# Summenstatistik aller 13 Featuresprint(wine.data.describe().to_string())
print()max_std_col = wine.data.std().idxmax()print(f"Größte Standardabweichung: {max_std_col} ({wine.data.std()[max_std_col]:.2f})")| Kennzahl | Beschreibung |
|---|---|
count | Anzahl der Einträge |
mean | Mittelwert |
std | Standardabweichung, wie stark die Werte streuen |
min | Kleinster Wert |
25% | Unteres Quartil |
50% | Median |
75% | Oberes Quartil |
max | Größter Wert |
Die Variable proline besitzt mit einem Wert von 314.91 die größte Standardabweichung. Die Größenordnungen der Spalten unterscheiden sich stark, was eine Skalierung empfehlenswert macht (siehe h)).
d) Korrelationsplot
Section titled “d) Korrelationsplot”Erstellen Sie einen Korrelationsplot für wine.data. Welche Variablen sind am stärksten korreliert?
Lösung:
from sklearn.datasets import load_wineimport seaborn as snsimport matplotlib.pyplot as plt
wine = load_wine(as_frame=True)
sns.heatmap(wine.data.corr(), annot=True, fmt='.2f', cmap='coolwarm')plt.tight_layout()plt.show()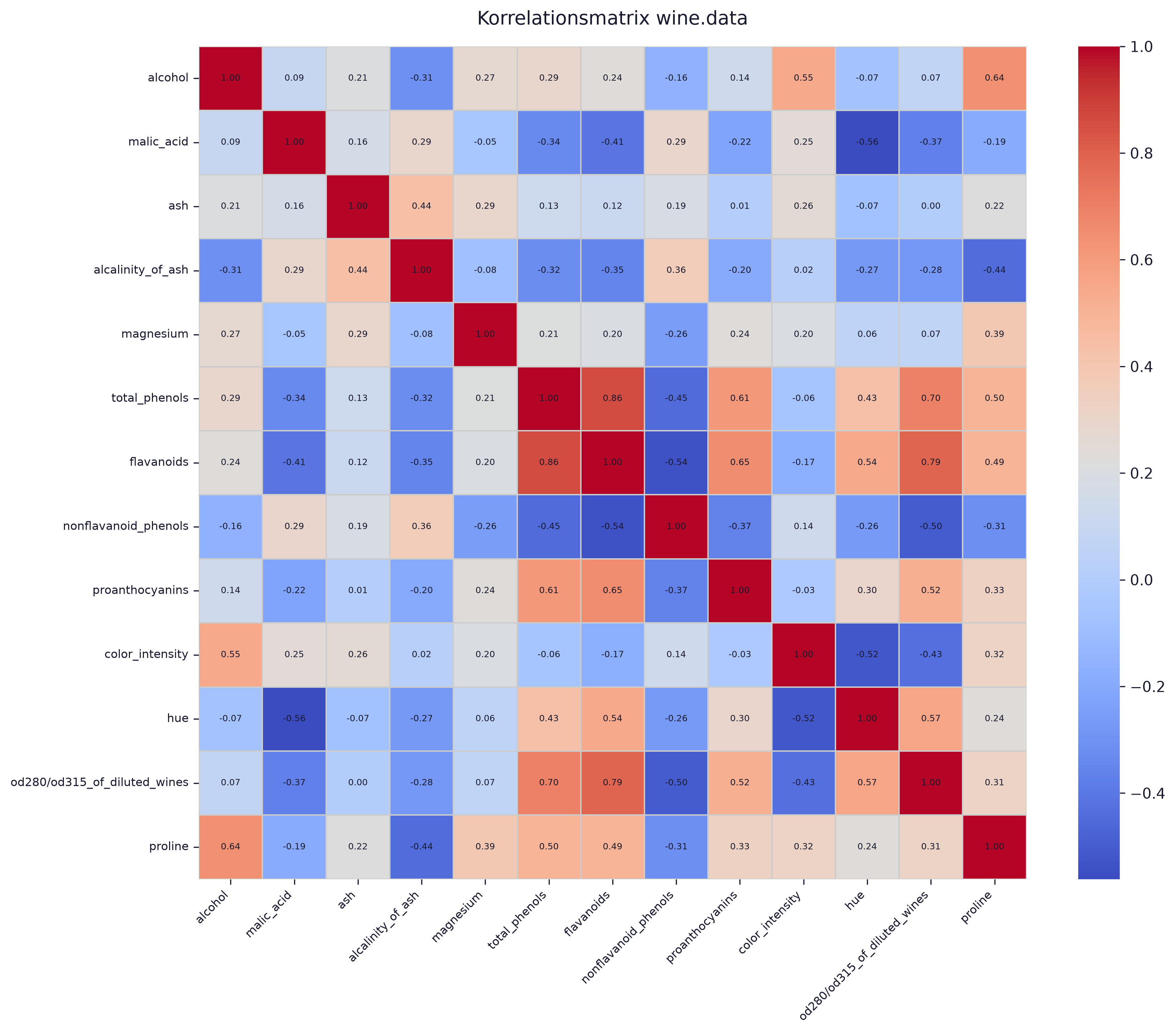
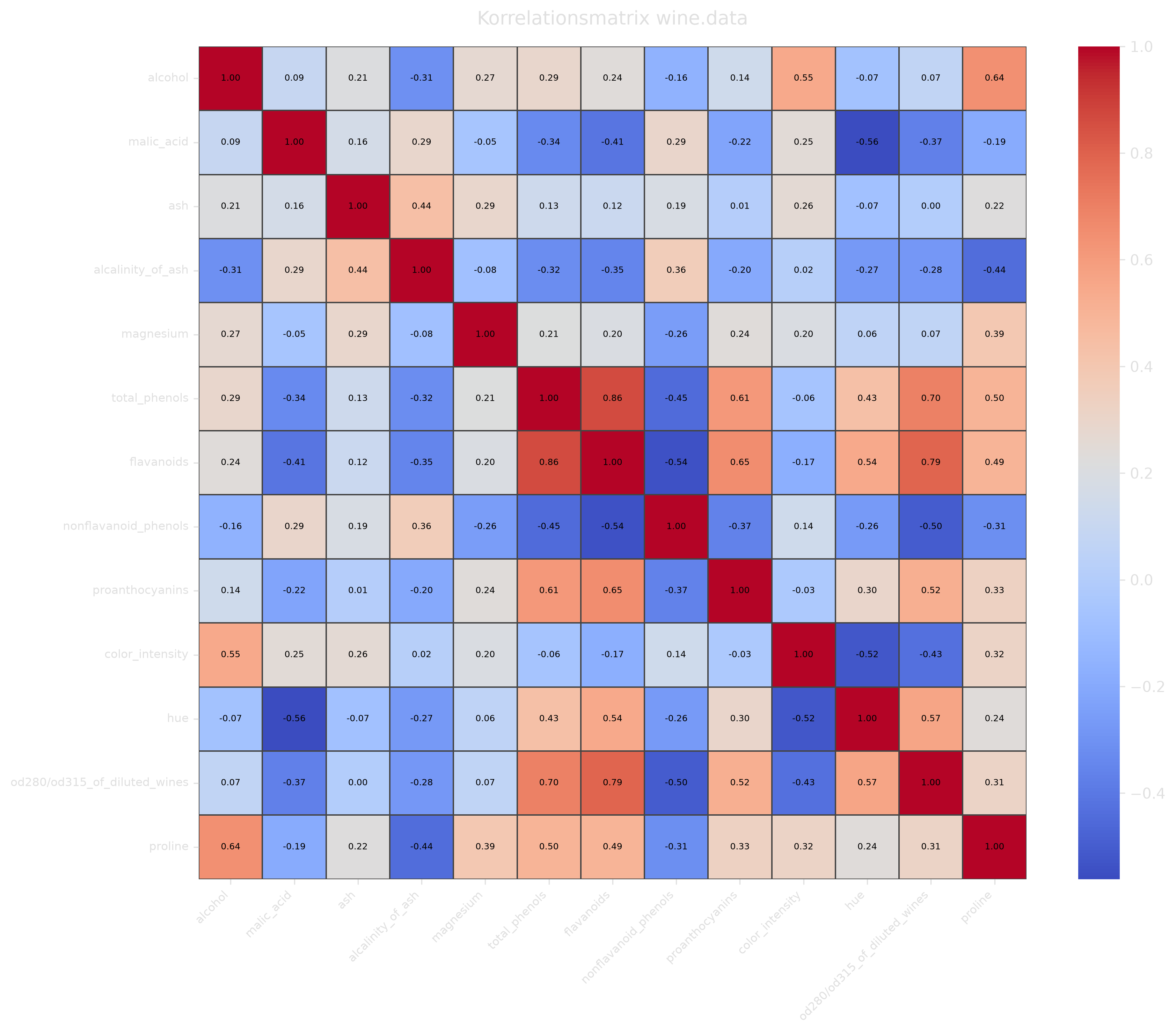
flavanoids und total_phenols zeigen mit einem Korrelationskoeffizient von 0.86 die stärkste Korrelation im Datensatz.
e) Pairplot
Section titled “e) Pairplot”Kombinieren Sie wine.data und wine.target zu einem neuen Datensatz und erstellen Sie einen Pairplot.
Welche Bedeutung haben die Graphen auf der Diagonalen (von links oben nach rechts unten) des Pairplot?
In welcher Zeile des Pairplot sind die Cluster am deutlichsten erkennbar?
Lösung:
from sklearn.datasets import load_wineimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as plt
wine = load_wine(as_frame=True)
# wine.data und wine.target zu einem DataFrame kombinierendf = pd.concat([wine.data, wine.target], axis=1)
sns.pairplot(df, hue='target', plot_kws={'alpha': 0.5, 's': 8})plt.show()
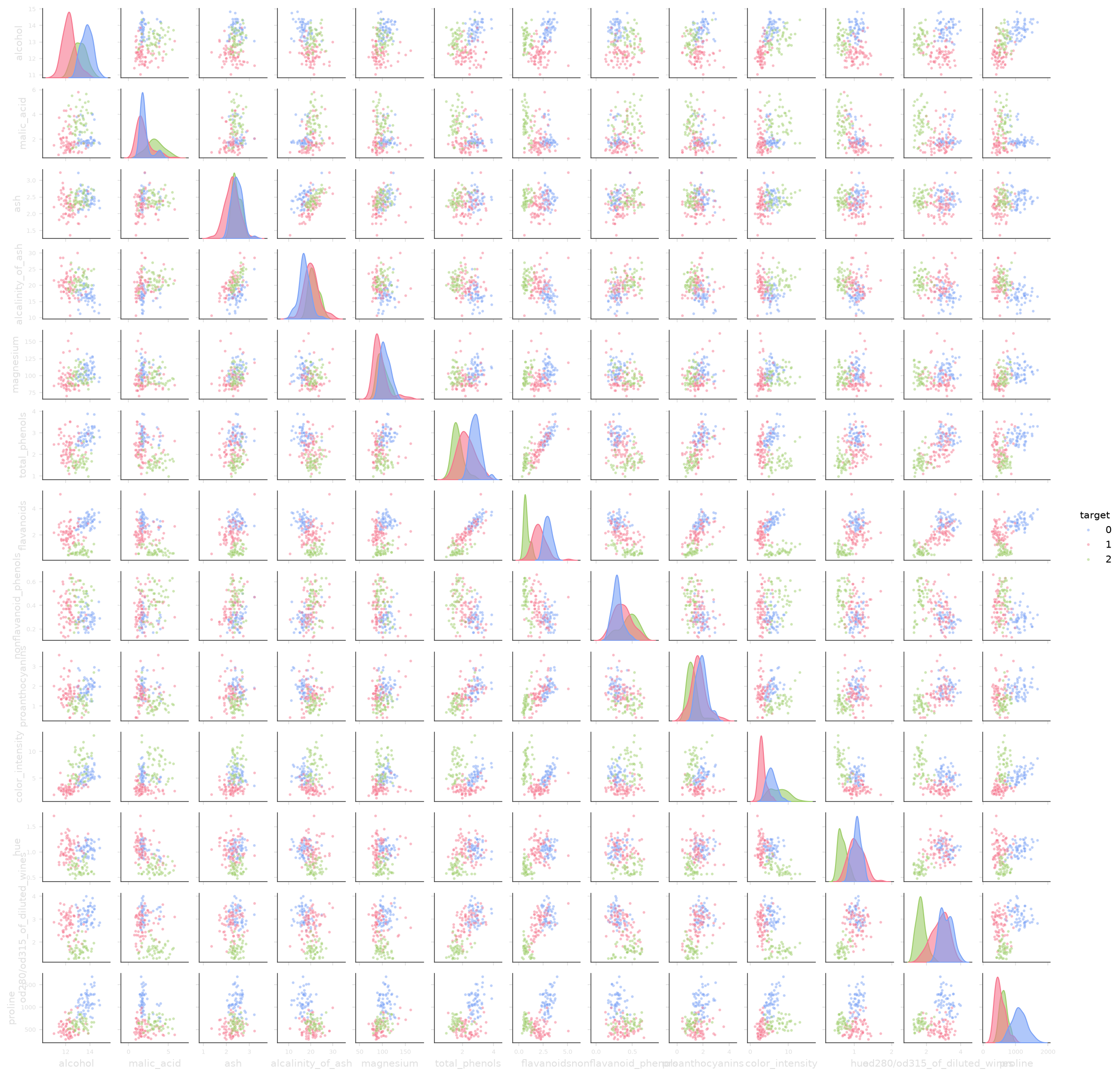
Die Graphen auf der Diagonalen zeigen die Verteilung (KDE) jedes einzelnen Features getrennt nach Klasse. Sie geben Aufschluss darüber, wie stark sich die drei Weinklassen in diesem Feature unterscheiden.
In der Zeile flavanoids sind die drei Cluster am deutlichsten erkennbar, da die Punktwolken der drei Klassen dort am klarsten voneinander getrennt sind.
f) Ellenbogen-Methode
Section titled “f) Ellenbogen-Methode”Welche Cluster-Anzahl liefert Ihnen die Ellenbogen-Methode für diesen Datensatz?
Lösung:
from sklearn.datasets import load_winefrom sklearn.cluster import KMeansimport matplotlib.pyplot as plt
wine = load_wine(as_frame=True)
# Inertia (WCSS) für k=1 bis 10 berechneninertias = []K = range(1, 11)for k in K: km = KMeans(n_clusters=k, random_state=42, n_init=10) km.fit(wine.data) inertias.append(km.inertia_ / 1e6) # in Millionen für bessere Lesbarkeit
fig, ax = plt.subplots(figsize=(8, 5))ax.plot(list(K), inertias, marker='o')ax.set_xlabel('Anzahl Cluster (k)')ax.set_ylabel('Inertia (in Mio.)')ax.set_title('Ellenbogen-Methode (unscaled)')ax.set_xticks(list(K))plt.tight_layout()plt.show()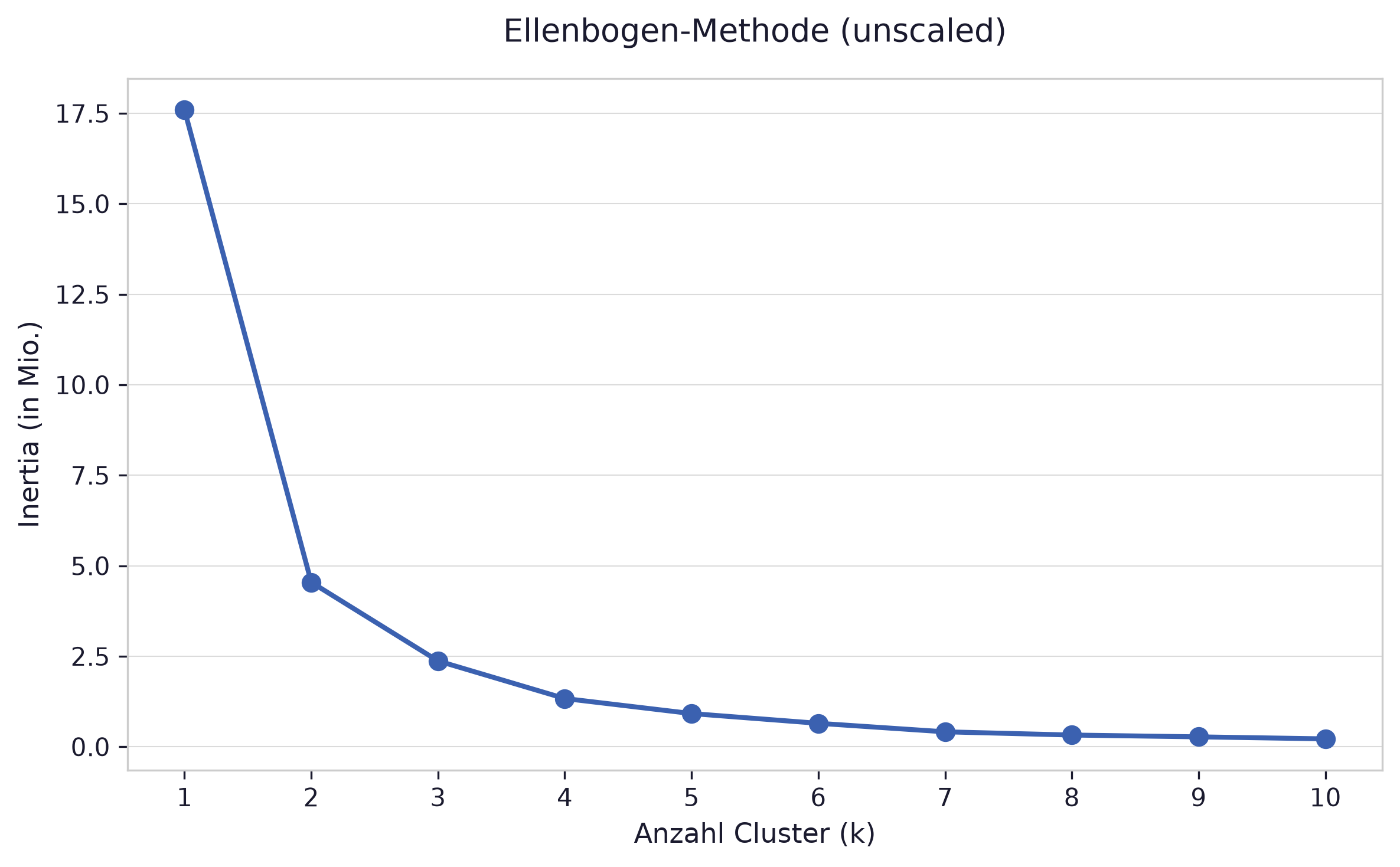
Die Ellenbogen-Methode liefert k=2 als optimale Cluster-Anzahl. Der Knick in der Kurve ist bei k=2 klar erkennbar: ab dort flacht die Kurve deutlich ab und weiterer Zugewinn durch mehr Cluster ist gering.
g) K-Means-Clustering
Section titled “g) K-Means-Clustering”Visualisieren Sie die Clusterung der Daten mittels K-Means-Clustering mit Ihrem Ergebnis aus Aufgabenteil f).
Lösung:
from sklearn.datasets import load_winefrom sklearn.cluster import KMeansfrom sklearn.decomposition import PCAimport matplotlib.pyplot as plt
wine = load_wine(as_frame=True)
# K-Means mit k=2 (Ergebnis aus f))km = KMeans(n_clusters=2, random_state=42, n_init=10)labels = km.fit_predict(wine.data)
# PCA auf 2 Komponenten zur Visualisierung (13 Features lassen sich nicht direkt plotten)pca = PCA(n_components=2)coords = pca.fit_transform(wine.data)
fig, ax = plt.subplots(figsize=(8, 6))for i, color in enumerate(['steelblue', 'tomato']): mask = labels == i ax.scatter(coords[mask, 0], coords[mask, 1], c=color, s=30, alpha=0.7, label=f'Cluster {i}')ax.set_xlabel('PC 1')ax.set_ylabel('PC 2')ax.set_title('K-Means-Clustering (k=2) – PCA-Projektion')ax.legend()plt.tight_layout()plt.show()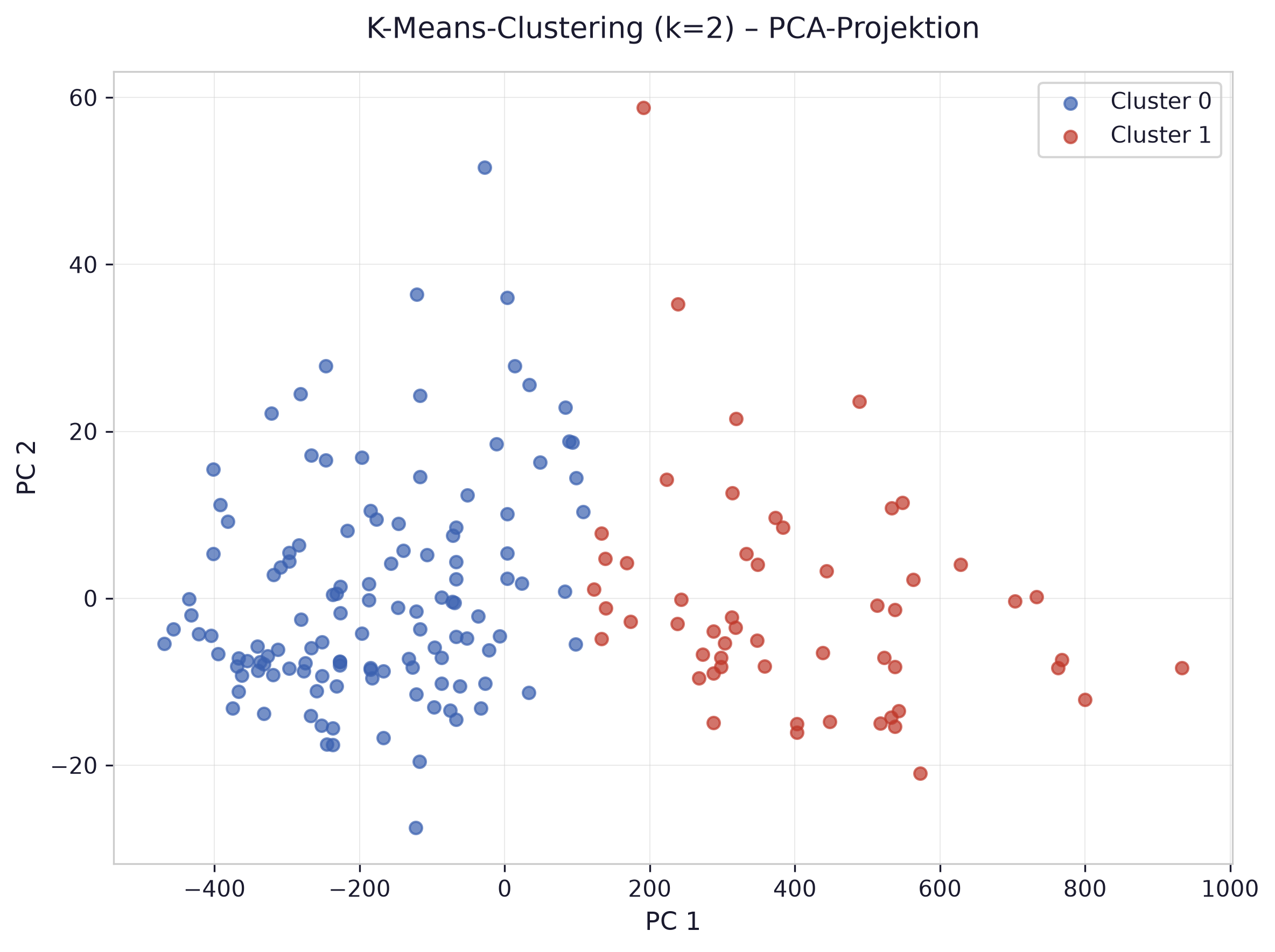
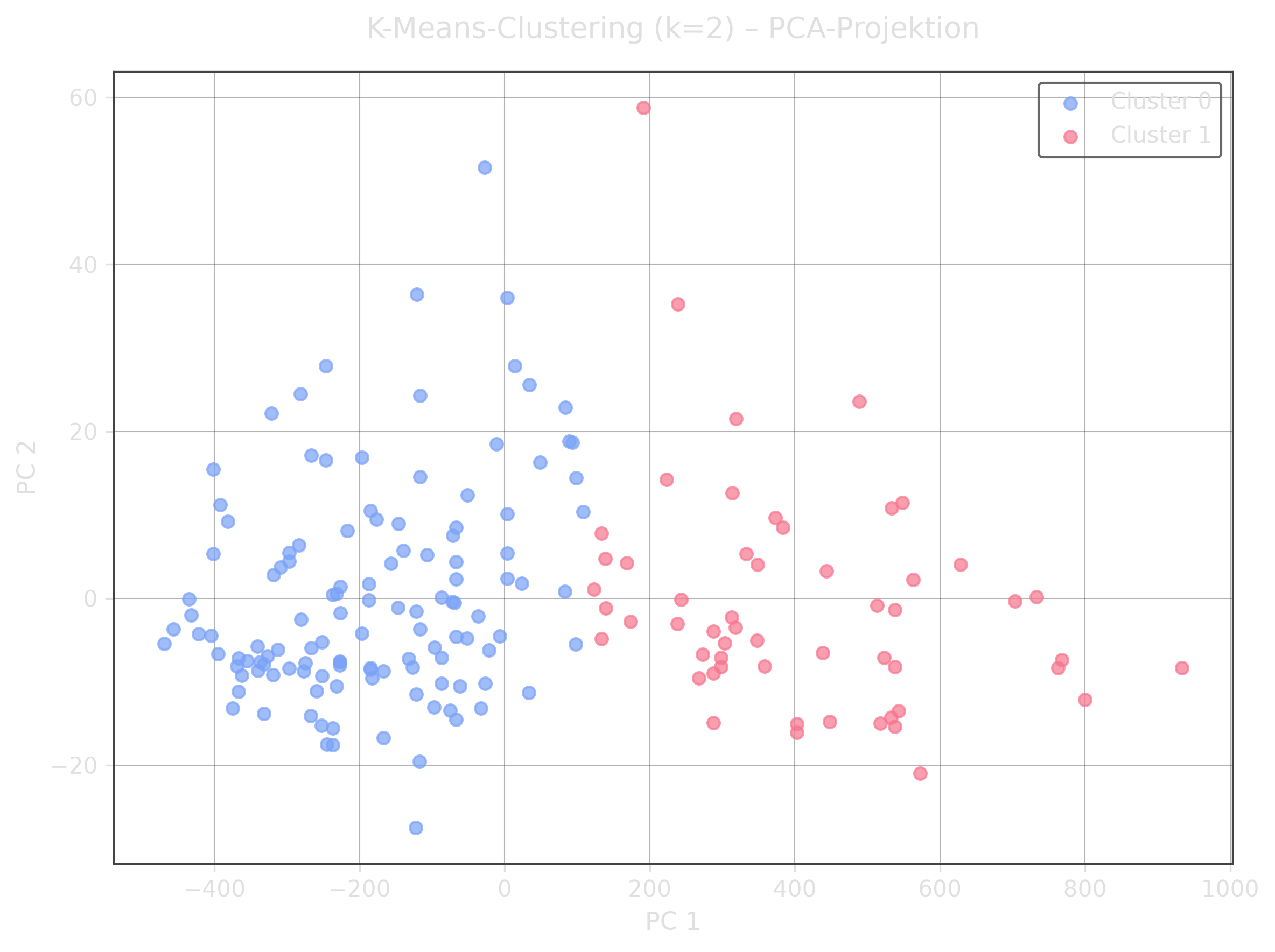
Da der Datensatz 13 Features besitzt, können die Cluster nicht direkt in einem 2D-Plot dargestellt werden. PCA reduziert die 13 Dimensionen auf 2 Hauptkomponenten, die den Großteil der Varianz erhalten. Die zwei farbigen Punktwolken zeigen die gefundenen Cluster.
h) Skalierter Datensatz
Section titled “h) Skalierter Datensatz”Wie Aufgabenteil c) zeigt, sind die Größenordnungen der Spalten des Datensatzes unterschiedlich, somit ist eine Skalierung empfehlenswert. Dies lässt sich vergleichsweise einfach über die Klasse StandardScaler im Paket sklearn.preprocessing bewerkstelligen:
from sklearn.preprocessing import StandardScalerscaled = StandardScaler().fit_transform(wine.data)df = pd.DataFrame(scaled)Welchen Wert für K liefert Ihnen die Ellenbogen-Methode für den skalierten Datensatz? Wie bewerten Sie dieses Ergebnis?
Lösung:
from sklearn.datasets import load_winefrom sklearn.cluster import KMeansfrom sklearn.preprocessing import StandardScalerimport pandas as pdimport matplotlib.pyplot as plt
wine = load_wine(as_frame=True)
# Datensatz skalierenscaled = StandardScaler().fit_transform(wine.data)df = pd.DataFrame(scaled)
# Ellenbogen-Methode auf skalierten Dateninertias = []K = range(1, 11)for k in K: km = KMeans(n_clusters=k, random_state=42, n_init=10) km.fit(df) inertias.append(km.inertia_)
fig, ax = plt.subplots(figsize=(8, 5))ax.plot(K, inertias, marker='o')ax.set_xlabel('Anzahl Cluster (k)')ax.set_ylabel('Inertia (WCSS)')ax.set_title('Ellenbogen-Methode (scaled)')ax.set_xticks(list(K))plt.tight_layout()plt.show()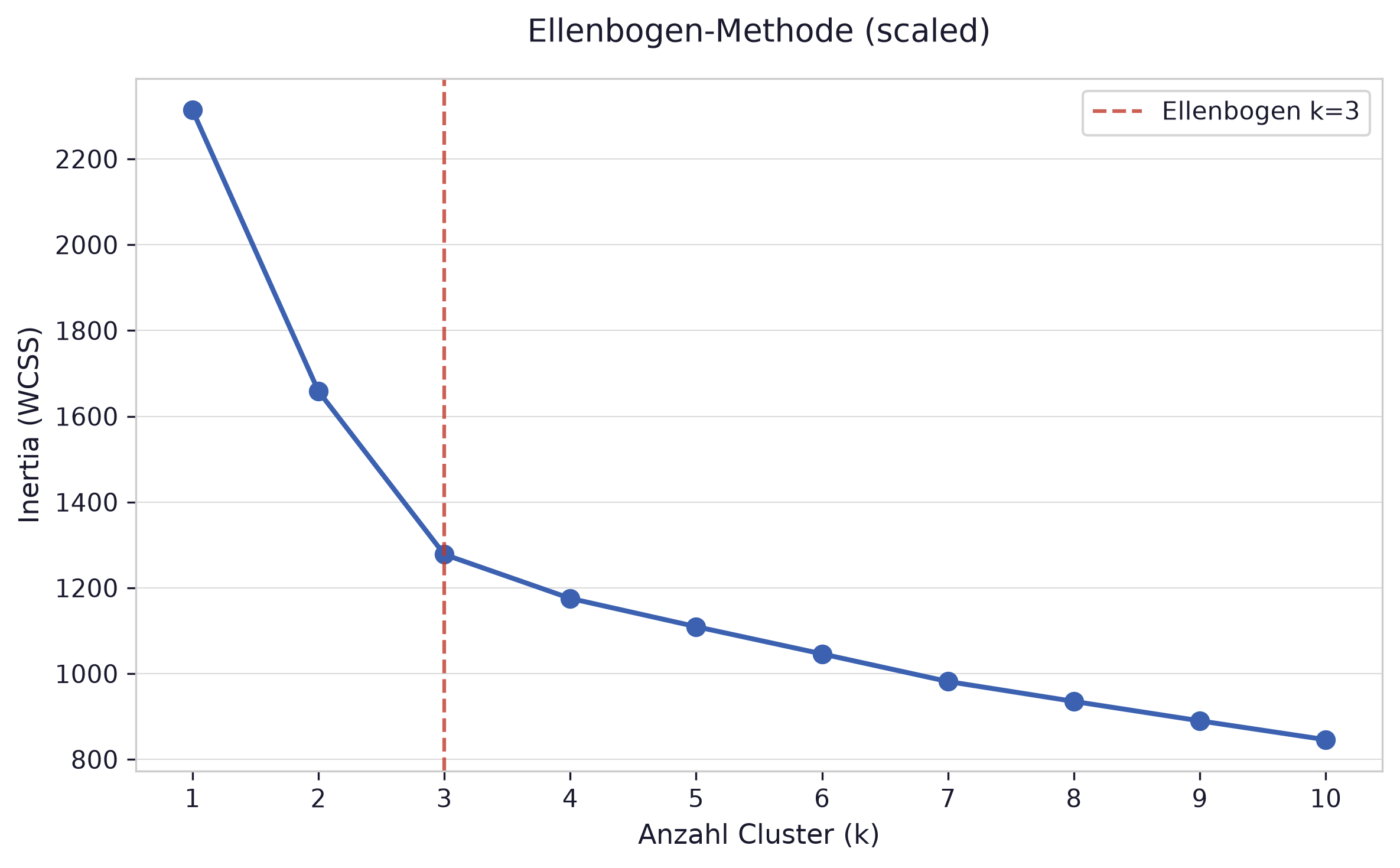
Der skalierte Datensatz liefert k=3, der Knick ist nun deutlich klarer erkennbar als in f). Das Ergebnis ist sinnvoll: der wine-Datensatz enthält tatsächlich drei Klassen (drei verschiedene Weinbauern).
Ohne Skalierung dominiert proline mit seiner großen Standardabweichung (314) die Distanzberechnung von K-Means, die anderen 12 Features werden kaum berücksichtigt. Das führt zu einem verzerrten Ergebnis (k=2). Nach der Skalierung tragen alle Features gleichmäßig bei und K-Means findet die tatsächliche Struktur im Datensatz.