Aufgabe 1 - Explorative Analyse
Der Datensatz movies2019.csv enthält die im Jahr 2019 erschienenen Filme, kategorisiert nach Filmstudio (Distributor) und Genre sowie die mit dem jeweiligen Film erzielten Umsätze (2019 Gross).
| Rank | Movie | Release Date | Distributor | Genre | 2019 Gross | Tickets Sold |
|---|---|---|---|---|---|---|
| 1 | Avengers: Endgame | Apr 26, 2019 | Walt Disney | Action | $857,190,335 | 94,093,340 |
| 2 | Captain Marvel | Mar 8, 2019 | Walt Disney | Action | $426,829,839 | 46,852,891 |
| 3 | Toy Story 4 | Jun 21, 2019 | Walt Disney | Adventure | $404,979,743 | 44,454,417 |
| … | … | … | … | … | … | … |
a) DataFrame einlesen
Section titled “a) DataFrame einlesen”Lesen Sie den Datensatz in einen Pandas DataFrame ein und zeigen Sie die ersten fünf Zeilen an.
Lösung:
import pandas as pd
df = pd.read_csv('movies2019.csv')print(df.head().to_string())b) Count Plot
Section titled “b) Count Plot”Erstellen Sie einen Count Plot der Spalte Genre. Achten Sie auf eine geeignete Größe für den Plot.
Lösung:
import pandas as pdimport matplotlib.pyplot as plt
df = pd.read_csv('movies2019.csv')
# Häufigkeit jedes Genres zählengenre_counts = df['Genre'].value_counts()
# figsize=(12, 5) sorgt für genug Breite, damit die Genre-Labels nicht überlappenfig, ax = plt.subplots(figsize=(12, 5))ax.bar(genre_counts.index, genre_counts.values)
ax.set_xlabel('Genre')ax.set_ylabel('Anzahl Filme')ax.set_title('Anzahl Filme pro Genre')
# Labels um 30° drehen, damit sie leserlich bleibenplt.xticks(rotation=30, ha='right')plt.tight_layout()plt.show()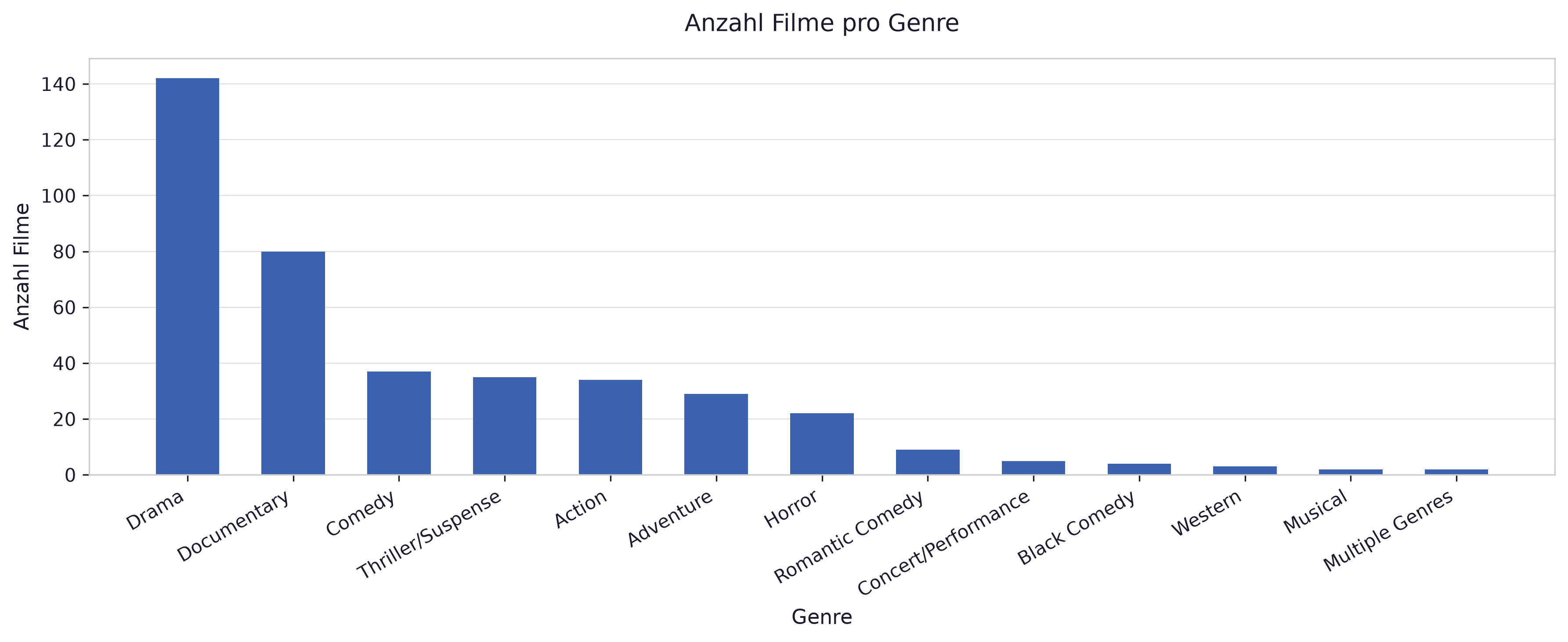
c) Datentyp-Konvertierung
Section titled “c) Datentyp-Konvertierung”Der Typ der Spalte 2019 Gross ist String. Um mit dieser Spalte weiterarbeiten zu können, müssen die Strings in Zahlenwerte gewandelt werden.
Führen Sie diese Umwandlung durch und ermitteln Sie den Gesamtumsatz der 2019 veröffentlichten Filme.
Hinweis: Wenden Sie die Funktion
applyauf die Spalte2019 Grossmit einer geeigneten Funktion an.
Lösung:
import pandas as pd
df = pd.read_csv('movies2019.csv')
# Schritt 1: $ und Kommas entfernen, dann zu float konvertierendf['2019 Gross'] = df['2019 Gross'].apply(lambda x: float(x.replace('$', '').replace(',', '')))
# Schritt 2: Gesamtumsatz summierentotal = df['2019 Gross'].sum()print(f'Gesamtumsatz 2019: ${total:,.0f}')d) Summenstatistik nach Genre
Section titled “d) Summenstatistik nach Genre”Erstellen Sie eine Summenstatistik für die Spalte 2019 Gross nach Genre. In welche Genres fallen die meisten bzw. wenigsten Filme?
Hinweis: Verwenden Sie die DataFrame-Methode
groupby.
Lösung:
import pandas as pd
df = pd.read_csv('movies2019.csv')df['2019 Gross'] = df['2019 Gross'].apply(lambda x: float(x.replace('$', '').replace(',', '')))
# Gesamtumsatz nach Genreumsatz = df.groupby('Genre')['2019 Gross'].sum().sort_values(ascending=False)print("Gesamtumsatz nach Genre:")print(umsatz.apply(lambda x: f'${x:,.0f}').to_string())
print()
# Anzahl Filme nach Genreanzahl = df.groupby('Genre').size().sort_values(ascending=False)print("Anzahl Filme nach Genre:")print(anzahl.to_string())
print()print(f"Meisten Filme: {anzahl.index[0]} ({anzahl.iloc[0]})")print(f"Wenigsten Filme: {anzahl.index[-1]} ({anzahl.iloc[-1]})")e) Barplot nach Genre
Section titled “e) Barplot nach Genre”Erstellen Sie einen Barplot mit Genre auf der x-Achse und Gesamtumsatz auf der y-Achse. Wählen Sie wieder eine geeignete Größe für den Plot.
Lösung:
import pandas as pdimport matplotlib.pyplot as plt
df = pd.read_csv('movies2019.csv')df['2019 Gross'] = df['2019 Gross'].apply(lambda x: float(x.replace('$', '').replace(',', '')))
# Gesamtumsatz pro Genre summieren und absteigend sortierenumsatz = df.groupby('Genre')['2019 Gross'].sum().sort_values(ascending=False)
# figsize=(12, 5) sorgt für genug Breite, damit die Genre-Labels nicht überlappenfig, ax = plt.subplots(figsize=(12, 5))ax.bar(umsatz.index, umsatz.values / 1e9)
ax.set_xlabel('Genre')ax.set_ylabel('Gesamtumsatz (in Mrd. $)')ax.set_title('Gesamtumsatz 2019 nach Genre')plt.xticks(rotation=30, ha='right')plt.tight_layout()plt.show()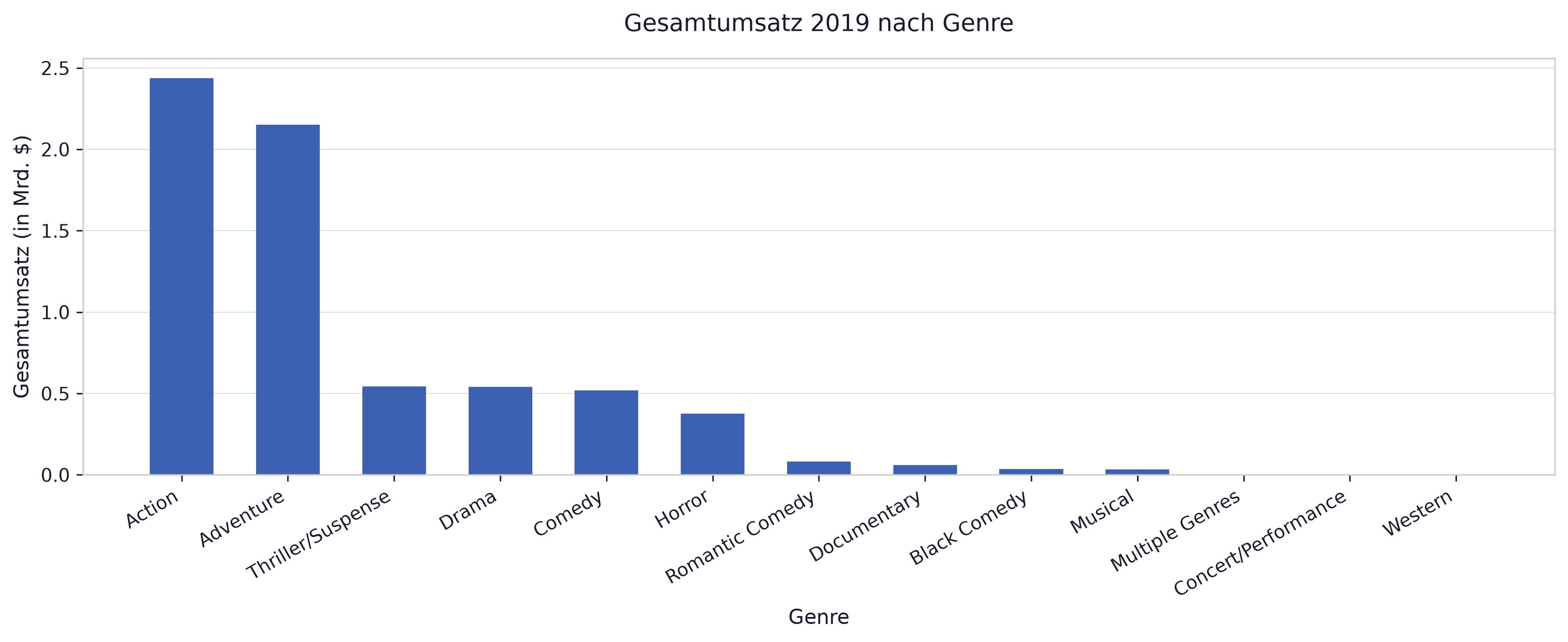
f) Barplot nach Monat
Section titled “f) Barplot nach Monat”Erstellen Sie einen Barplot, der die Gesamtumsätze nach Monat der Erscheinung visualisiert.
Hinweis: Sie müssen eine Transformation der Spalte
Release Datedurchführen.
Lösung:
import pandas as pdimport matplotlib.pyplot as plt
df = pd.read_csv('movies2019.csv')df['2019 Gross'] = df['2019 Gross'].apply(lambda x: float(x.replace('$', '').replace(',', '')))
# Monat aus Release Date extrahierendf['Monat_num'] = pd.to_datetime(df['Release Date']).dt.monthdf['Monat_name'] = pd.to_datetime(df['Release Date']).dt.strftime('%b')
# Gesamtumsatz nach Monat, chronologisch sortiertmonat_umsatz = df.groupby(['Monat_num', 'Monat_name'])['2019 Gross'].sum().reset_index()monat_umsatz = monat_umsatz.sort_values('Monat_num')
fig, ax = plt.subplots(figsize=(12, 5))ax.bar(monat_umsatz['Monat_name'], monat_umsatz['2019 Gross'] / 1e9)
ax.set_xlabel('Monat')ax.set_ylabel('Gesamtumsatz (in Mrd. $)')ax.set_title('Gesamtumsatz 2019 nach Erscheinungsmonat')plt.tight_layout()plt.show()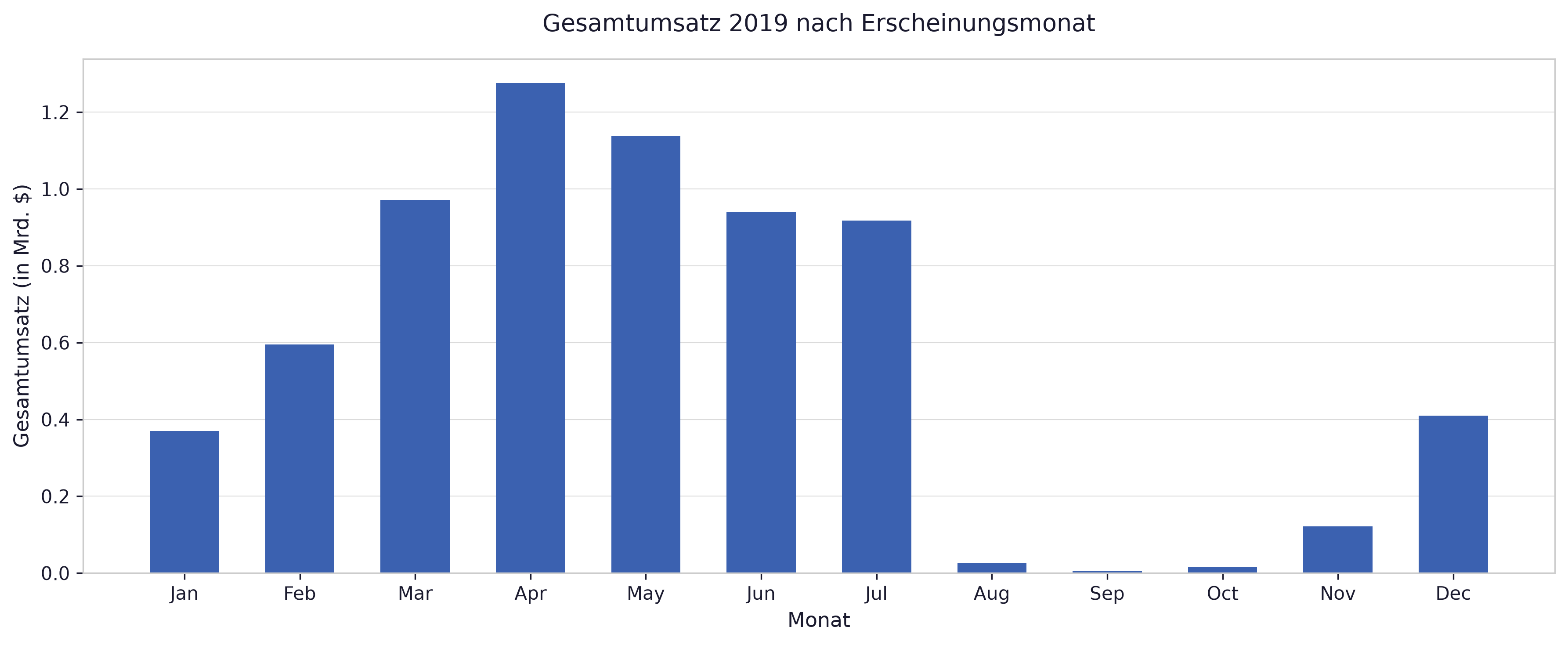
g) Top-Distributoren
Section titled “g) Top-Distributoren”Summieren Sie die Gesamtumsätze 2019 gruppiert nach Distributor und sortieren Sie absteigend. Welche fünf Distributoren haben den größten Gesamtumsatz 2019 erzielt? Nennen Sie diese.
Lösung:
import pandas as pd
df = pd.read_csv('movies2019.csv')df['2019 Gross'] = df['2019 Gross'].apply(lambda x: float(x.replace('$', '').replace(',', '')))
# Gesamtumsatz nach Distributor gruppieren und absteigend sortieren (alle 22 Distributoren)umsatz = df.groupby('Distributor')['2019 Gross'].sum().sort_values(ascending=False)
# Nur die Top 5 ausgebenprint("Top 5 Distributoren nach Gesamtumsatz 2019:")print()for i, (name, wert) in enumerate(umsatz.head(5).items(), 1): print(f"{i}. {name}: ${wert:,.0f}")h) Fehlende Information
Section titled “h) Fehlende Information”Welche Information fehlt in diesem Datensatz, um den „Erfolg” eines Distributors beurteilen zu können?
Lösung:
Es fehlen die Produktionskosten bzw. das Budget der Filme. Nur anhand des Umsatzes lässt sich kein Rückschluss auf die Profitabilität ziehen. Ein Film mit hohem Umsatz kann trotzdem ein wirtschaftlicher Misserfolg sein, wenn das Budget noch höher war.