Aufgabe 2 - Lineare Regression und Entscheidungsbäume
In dieser Aufgabe verwenden wir den Datensatz „California Housing”. Der California-Housing-Datensatz ist Bestandteil der Bibliothek sklearn.datasets und kann über die Anweisung
california = sklearn.datasets.fetch_california_housing()geladen werden.
a) Datensatz laden
Section titled “a) Datensatz laden”Importieren Sie alle erforderlichen Bibliotheken, laden Sie den Datensatz und geben Sie eine Beschreibung des Datensatzes aus.
Geben Sie in dieser und in den folgenden Teilaufgaben die erforderlichen Python-Anweisungen an (die Ausgaben müssen Sie nicht angeben).
Beschreiben Sie kurz die Attribute des Datensatzes.
Lösung:
import sklearn.datasets
california = sklearn.datasets.fetch_california_housing()print(california.DESCR)Der Datensatz enthält 20.640 Instanzen mit 8 numerischen Attributen:
| Attribut | Beschreibung |
|---|---|
MedInc | Median-Einkommen in der Blockgruppe |
HouseAge | Medianes Alter der Häuser in der Blockgruppe |
AveRooms | Durchschnittliche Anzahl Zimmer pro Haushalt |
AveBedrms | Durchschnittliche Anzahl Schlafzimmer pro Haushalt |
Population | Bevölkerung der Blockgruppe |
AveOccup | Durchschnittliche Anzahl Haushaltsmitglieder |
Latitude | Geografische Breite der Blockgruppe |
Longitude | Geografische Länge der Blockgruppe |
Die Zielvariable MedHouseVal ist der mediane Hauswert in 100.000 USD.
b) DataFrame konvertieren
Section titled “b) DataFrame konvertieren”Konvertieren Sie den Datensatz in einen Pandas-DataFrame.
Lösung:
import sklearn.datasetsimport pandas as pd
california = sklearn.datasets.fetch_california_housing()
# Feature-Spalten aus dem Datensatz übernehmendf = pd.DataFrame(california.data, columns=california.feature_names)
# Zielvariable (medianer Hauswert) als eigene Spalte anhängendf['MedHouseVal'] = california.target
print(df.head().to_string())c) Summenstatistik
Section titled “c) Summenstatistik”Zeigen Sie eine Summenstatistik des Datensatzes an. Wie lautet der Mittelwert der Spalte HouseAge?
Lösung:
import sklearn.datasetsimport pandas as pd
california = sklearn.datasets.fetch_california_housing()df = pd.DataFrame(california.data, columns=california.feature_names)df['MedHouseVal'] = california.target
# Summenstatistik (count, mean, std, min, quartile, max)print(df.describe().to_string())
print()print(f"Mittelwert HouseAge: {df['HouseAge'].mean():.2f}")| Kennzahl | Beschreibung |
|---|---|
count | Anzahl der Einträge (keine fehlenden Werte wenn gleich 20.640) |
mean | Mittelwert |
std | Standardabweichung, wie stark die Werte streuen |
min | Kleinster Wert |
25% | Unteres Quartil, 25% der Werte liegen darunter |
50% | Median, die Mitte der Verteilung |
75% | Oberes Quartil, 75% der Werte liegen darunter |
max | Größter Wert |
Der Mittelwert von HouseAge beträgt 28.64.
d) Pairplot
Section titled “d) Pairplot”Erstellen Sie einen Pairplot des California-Housing-Datensatzes (erforderliche Bibliothek importieren nicht vergessen!).
Sind lineare Zusammenhänge zwischen den unabhängigen Variablen bzw. den unabhängigen Variablen und der Zielvariable erkennbar?
Lösung:
import sklearn.datasetsimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as plt
california = sklearn.datasets.fetch_california_housing()df = pd.DataFrame(california.data, columns=california.feature_names)df['MedHouseVal'] = california.target
sns.pairplot(df, plot_kws={'alpha': 0.2, 's': 2})plt.show()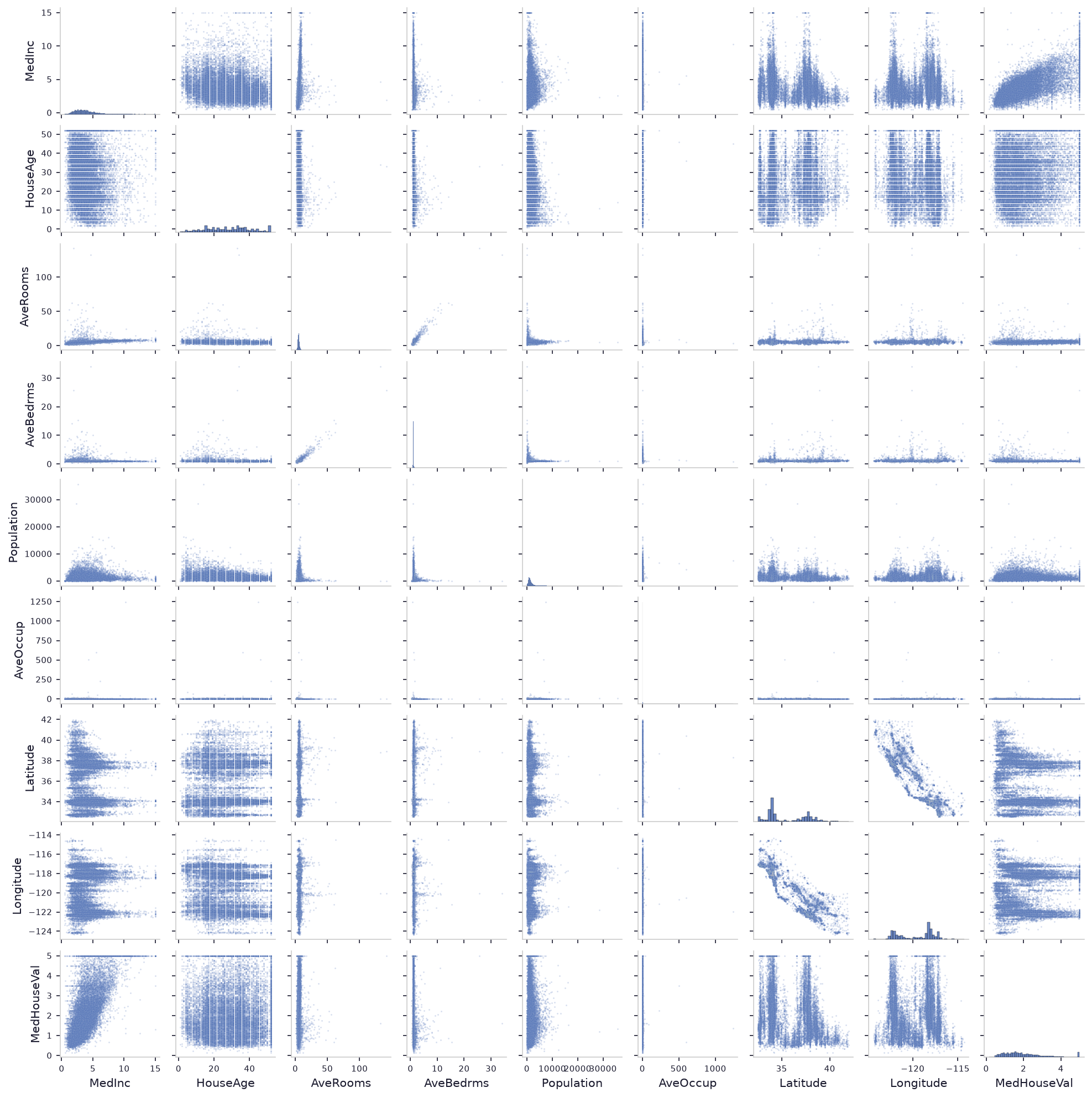
Aus dem Plot lässt sich ablesen dass MedInc den deutlichsten linearen Zusammenhang mit der Zielvariablen MedHouseVal zeigt (letzte Spalte / letzte Zeile). Ebenfalls erkennbar ist ein linearer Zusammenhang zwischen AveRooms und AveBedrms. Die anderen Variablen zeigen keine klar erkennbaren linearen Zusammenhänge, die Punkte streuen zu stark oder bilden keine gerade Linie.
e) Korrelationsplot
Section titled “e) Korrelationsplot”Erstellen Sie einen Korrelationsplot. Welche der unabhängigen Variablen zeigt die größte Korrelation mit der Zielvariablen?
Lösung:
import sklearn.datasetsimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as plt
california = sklearn.datasets.fetch_california_housing()df = pd.DataFrame(california.data, columns=california.feature_names)df['MedHouseVal'] = california.target
sns.heatmap(df.corr(), annot=True, fmt='.2f', cmap='coolwarm')plt.tight_layout()plt.show()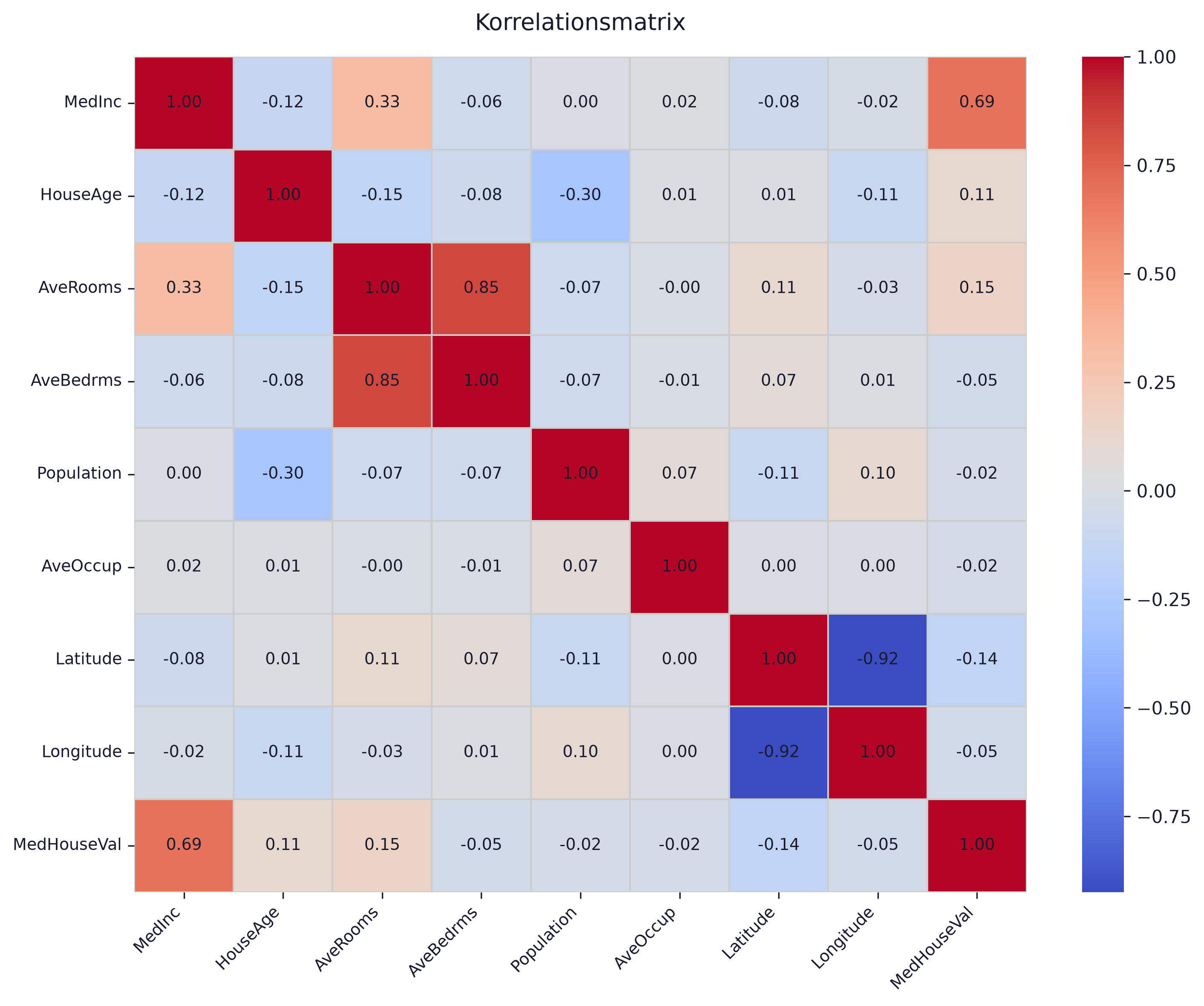
MedInc zeigt mit einem Korrelationskoeffizient von 0.69 die größte Korrelation mit der Zielvariablen MedHouseVal.
f) Lineare Regression
Section titled “f) Lineare Regression”Splitten Sie den Datensatz in Test- und Trainingsdaten auf.
Erstellen Sie dann ein lineares Regressionsmodell ohne die beiden Spalten Latitude und Longitude.
Wie lauten der Mean Squared Error und der R² Score?
Lösung:
import sklearn.datasetsimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_error, r2_score
california = sklearn.datasets.fetch_california_housing()df = pd.DataFrame(california.data, columns=california.feature_names)df['MedHouseVal'] = california.target
# Latitude und Longitude entfernendf = df.drop(columns=['Latitude', 'Longitude'])
# Features und Zielvariable trennenX = df.drop(columns=['MedHouseVal'])y = df['MedHouseVal']
# Train/Test Split (80% Training, 20% Test)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Lineares Regressionsmodell trainierenmodel = LinearRegression()model.fit(X_train, y_train)
# Vorhersage und Auswertungy_pred = model.predict(X_test)print(f"Mean Squared Error: {mean_squared_error(y_test, y_pred):.4f}")print(f"R² Score: {r2_score(y_test, y_pred):.4f}")| Kennzahl | Beschreibung |
|---|---|
MSE | Mean Squared Error, durchschnittlicher quadratischer Fehler zwischen Vorhersage und tatsächlichem Wert. Kleiner = besser. |
R² | Bestimmtheitsmaß, Anteil der erklärten Varianz. Wert zwischen 0 und 1, wobei 1 = perfekte Vorhersage. |
g) Entscheidungsbaum
Section titled “g) Entscheidungsbaum”Erstellen Sie nun ein Regressionsmodell (wieder ohne die Spalten Latitude und Longitude) mit einem Entscheidungsbaum.
Ab welcher maximalen Tiefe (depth) liefert dieses Modell bessere Resultate als die lineare Regression?
Lösung:
import sklearn.datasetsimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.tree import DecisionTreeRegressorfrom sklearn.metrics import r2_score
california = sklearn.datasets.fetch_california_housing()df = pd.DataFrame(california.data, columns=california.feature_names)df['MedHouseVal'] = california.targetdf = df.drop(columns=['Latitude', 'Longitude'])
X = df.drop(columns=['MedHouseVal'])y = df['MedHouseVal']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# R² der linearen Regression als Referenzwertlr = LinearRegression()lr.fit(X_train, y_train)r2_lr = r2_score(y_test, lr.predict(X_test))print(f"Lineare Regression R²: {r2_lr:.4f}")print()
# Entscheidungsbaum mit verschiedenen Tiefen testenprint(f"{'Tiefe':<8} {'R² Baum':<12} {'Besser als LR?'}")print("-" * 35)for depth in range(1, 11): tree = DecisionTreeRegressor(max_depth=depth, random_state=42) tree.fit(X_train, y_train) r2_tree = r2_score(y_test, tree.predict(X_test)) besser = "✓" if r2_tree > r2_lr else "" print(f"{depth:<8} {r2_tree:<12.4f} {besser}")Ab Tiefe 4 übertrifft der Entscheidungsbaum die lineare Regression. Ab Tiefe 9 beginnt der R² wieder zu sinken, der Baum passt sich zu stark an die Trainingsdaten an (Overfitting) und verliert die Fähigkeit auf neuen Daten zu generalisieren.
h) Einfluss der Koordinaten
Section titled “h) Einfluss der Koordinaten”In der Analyse haben wir die beiden Spalten Latitude und Longitude weggelassen. Auf welche Weise werden so die Ergebnisse der Regression verfälscht?
Wie könnten Sie grundsätzlich verfahren, um die beiden Spalten in der Regression zu berücksichtigen?
Lösung:
Lage ist ein entscheidender Faktor für Hauswerte (Küste vs. Inland, San Francisco vs. ländlich). Ohne Koordinaten ignoriert das Modell diesen geografischen Einfluss komplett, was zu systematischen Fehlern führt.
Man könnte Clustering auf Basis von Latitude/Longitude anwenden (z.B. Regionen bilden) und diese als kategoriale Variable ins Modell einbauen, oder ein komplexeres Modell wie einen Entscheidungsbaum nutzen der geografische Muster besser erfassen kann.